

He discusses the disruption that ebooks have caused in the publishing world and looks ahead to see what implications this has for Bible translations. Quoting the BibleTech 2013 conference description:
This talk explores the viability of using machine learning and other math-filled buzzwords to computationally derive an English translation of the Bible. While automated processes often produce nonsensical or uncanny-valley-style translations that are just wrong enough to be unnerving, do we have enough linguistic and semantic Bible data to produce a reasonable-quality automated translation of the Bible? And if so, what could such a translation and process look like?Using readily available technologies such as WordNet, Smith shows what something like this might look like at his Adaptive Bible website. As you can see in the slide below, for users, it's a matter of clicking through on various options of words/phrases in a verse that have been collected from a variety of English versions. (Choices made are in green. Probable next options in yellow.)
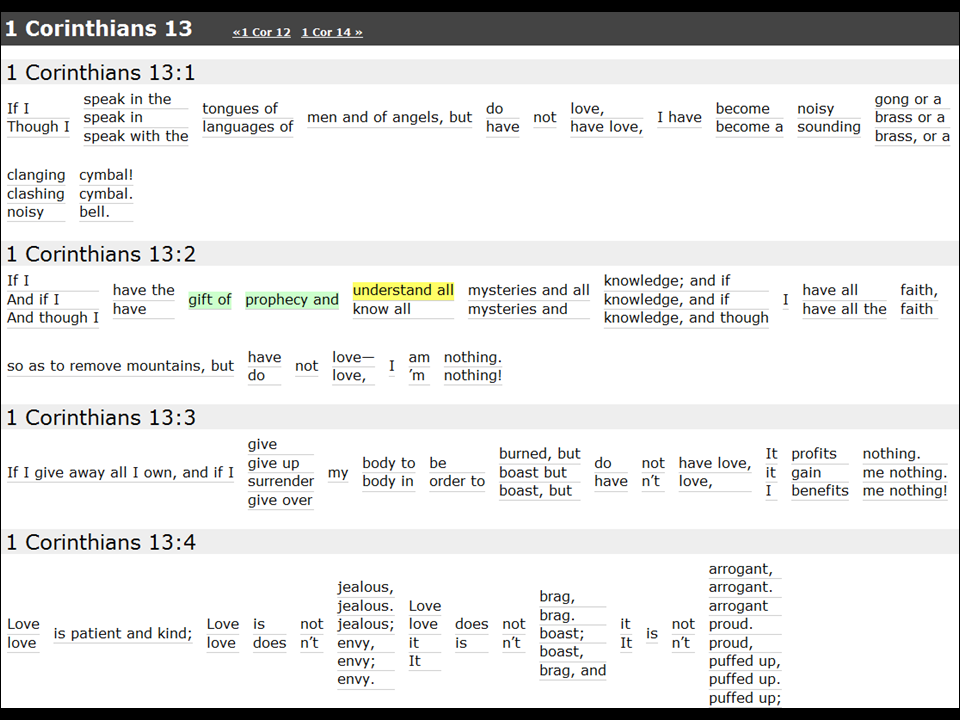
I'll add two comments of my own:
- What I’ve just described is one pretty basic approach to what I think is inevitable: the explosion of translations into Franken-Bibles as technology gets better. In the future, we won’t be talking about particular translations anymore but rather about trust networks.
- To be clear, I’m not saying that I think this development is a particularly great one for the church, and it’s definitely not good for existing Bible translations. But I do think it’s only a matter of time until Franken-Bibles arrive. At first they’ll be unwieldy and ridiculously bad, but over time they’ll adapt, improve, and will need to be taken seriously.
- This approach is a bit different because it starts with English versions, not the Greek original. I suppose this would get one closer to natural English more quickly, and Smith did note one by-product of what he was doing for creating semantic ranges of a particular Strong's number entry using WordNet.
- I'm also thinking that machine language translation tools will improve and become specialized so that eventually we will have the capability of translating from Koine (not modern) Greek into English. I also imagine that you would be able to create that translation and specify parameters regarding how literal/dynamic it is and reading level of the generated text.









